2009-10-26
Abstract
This is a report on the NEERI 09 meeting in Helsinki, trying to summarize the wealth of information from all the presentations and also additionaly explicate the broader context or dig deeper, where deemed necessary and feasible. There are by any means enough open questions and blind spots in it still.
The main two day event was accompanied by specialized workshop on standards organised jointly by FLARENET and CLARIN.
Program with all topics, speakers and their presentations is available on event's website: www.csc.fi/english/pages/neeri09
The words used most often were probably: metadata, interoperability and need.
NEERI 09 - Networking Event for European Research Infrastructures - was an event organised by the CLARIN Consortium, CSC - IT-Center for Science and the University of Helsinki, with the main goal to draw a more comprehensive picture of the European Research Infrastructures landscape and to allow and encourage the exchange of information and experience, i.e. enable networking between individual initiatives.
And indeed the organizers suceeded in bringing together a diverse audience and representatives from various RI intiatives presenting their specific perspectives.
In particular also two representatives of the European Commission explicated the point of view of the EC:
- Hervé Pero
-
Head of Research Infrastructures, EC
- Kostas Glinos
-
Head of Unit INFSO F3, EC; www.cordis.europa.eu/fp7/ict/e-infrastructure/
Approximately the half of the attendants and presenters were CLARIN members, the rest were people from other initiatives. Following the list of projects and organisations represented at the event:
- APA, Alliance for Permanent Access, www.alliancepermanentaccess.eu/
-
The Alliance aims to develop a shared vision and framework for a sustainable organisational infrastructure for permanent access to scientific information
- CESSDA, Council of European Social Science Data Archives, www.cessda.org/
-
established in 1976, it has currently 20+ members. More in chapter CESSDA
- METAFOR Climate, metaforclimate.eu
-
a FP7 project for developing a common metadata model for Climate Modelling Digital Repositories
- CNRI, Corporation for National Research Initiatives, www.cnri.reston.va.us
-
not-for-profit organization for strategic development of network-based information technologies, formed in 1986. Among other activities owner of the PID system: Handle System.
- DANS, Data Archiving & Networked Serivces, www.dans.knaw.nl
-
established in 2005, national organisation responsible for storing and providing permanent access to research data from the Humanities and Social Sciences. Provider of the archiving system EASY [easy.dans.knaw.nl/dms].
- DARIAH, Digital Research Infrastructure for the Arts and Humanities, dariah.eu
-
proposed in 2005, RI to connect scholarly data archives and repositories with cultural heritage for the arts and humanities across Europe, to facilitate long-term access to, and use of all European arts and humanities data for the purposes of research.
- DEISA, Distributed European Infrastructure for Supercomputing Applications, www.deisa.eu
-
deploys and operates a persistent, production quality, distributed supercomputing environment with continental scope, established in 2002. More in chapter DEISA
- DRIVER, Digital Repository Infrastructure Vision for European Research, www.driver-repository.eu
-
since 2006, a project to create a pan-European infrastructure for digital repositories of content resources (any form of scientific output). DRIVER European Confederation of Digital Repositories is the organisational incarnation.
- EGEE, Enabling Grids in E-sciencE, www.eu-egee.org
-
Europe's leading Grid computing project, providing a computing support infrastructure for over 10,000 researchers world-wide. Started before 2006 it is now in a transition phase toward a sustainable organisational model: European Grid Initiative. More in chapter EGEE.
- eIRG, e-Infrastructure Reflection Group, www.e-irg.eu
-
an advisory body to accompany the ESFRI efforts, established in 2003, formed by official delegations of ministries of science from all the European countries. More under in chapter Research Infrastructures.
- FLaReNet, Fostering Language Resources Network, www.flarenet.eu
-
a 3-years project funded in the framework of the eContentplus Programme started in 2007 with currently 221 individual subscribers, 81 institutional members. It is aimed at creation of a shared policy, a common vision, a roadmap, a plan of coherent actions to consolidate methods and architectures and integrate partial solutions.
- Lifewatch, www.lifewatch.eu
-
e-science and technology infrastructure for biodiversity data and observatories, since 2008
- TERENA, Trans-European Research and Education Networking Association, www.terena.org
-
a not-for-profit association of European NRENs formed in 1994, a forum to promote and develop international network infrastructures to support European research and education. Homebase of projects like eduGAIN and eduroam.
H. Pero, K. Glinos, D. Vandromme
Especially the presentations of the EC representatives were very helpful in making the RI landscape more tangible and the overall strategy of the EC recognizable. They emphasized the need for stronger cooperation between individual initiatives/infrastructures and thanked CLARIN for the NEERI meeting enabling the exchange of information among the projects.
Hervé Pero claimed CLARIN being more than a portal, it's actively helping to develop the eco-system and praised CLARIN for being a clear example of an EU research infrastructure fully integrating the EU e-infrastructures approaches.
He emphasized the idea of a "frontier research" - a research with vision, concentrated on grand challenges for Europe to stay at the forefront in the world`s research competition. This was relativized by Peter Wittenburg saying, that while focusing on the big vision we may not forget the "small challenges" - ie the everyday small tasks, which still have to be done. At the end both agreeing that we need both a long-perspective vision and the small steps to get there.
Kostas Glinos suggested a paradigm shift in the research - dubbed "e-Science" - evolvement towards big, complex data-intensive science of global dimension. This needs appropriate actions - changes in the research environment yielding the "e-Infrastructures". He coined "Europe as hub of excellence in e-Science".
The main technical issues wrt RI are discussed in section Technical aspects of RI. Another important topic is the legal and ethical issues.
Following a few key terms regarding research infrastructures:
- ESFRI, European Strategy Forum on Research Infrastructures, cordis.europa.eu/esfri/home.html
-
created in 2002, with the mission to support a coherent approach to policy-making on research infrastructures in Europe, and to act as an incubator for international negotiations about concrete initiatives. In particular, ESFRI is preparing a European Roadmap for new research infrastructures.
- ESFRI Roadmap, cordis.europa.eu/esfri/roadmap.htm
-
an on-going process of identifying new research infrastructures of pan-European interest, working towards a coherent overall environment - the European Research Area - in the research fields:
-
Social Science & Humanities
-
Environmental Sciences
-
Energy
-
Biomedical and Life Sciences
-
Material Sciences
-
Astronomy, Astrophysics, Nuclear and Particle Physics
-
Computer and Data Treatment
Currently 44 new projects (in their preparatory phase) are part of the roadmap. The total cost estimates amount to ~20B€ in ~ 10 years.
-
- European Research Area
-
a system of scientific research programmes established in 2000, with overall goal to build and sustain an attractive research environment, by creating a common market for research where the resources - researchers, technology and knowledge - can circulate freely.
- e-Infrastructure eco-system
-
All these initiatives can and should be seen as a common eco-system, together with many other already existing RI, amounting overall up to 150-200 European research infrastructures of variable size [PARADE] (H. Pero talking about 300 RIs supported under FP).
EC (ESFRI) sees itself as a high-level coordinating body and by no means the main funder: EC provides ~ 250 Mio. € a year which amount only to ~ 2,5 % of the overall volume needed for the infrastructures, the rest is expected to be raised by the national funds.
A crucial concern in building a research 'eco-system' is the integration and joint involvement of actors of all kinds: large (single-sited) facilities, distributed european facilities, regional partner facilities, network of national facilities but also universities & schools and industrial suppliers & users. e-Infrastructures lie at the core of the knowledge triangle Research-Education-Innovation.
This huge effort with a multitude of construction sites carries a great risk of fragmentation, creating incompatible infrastructures, disparate environments and raises a strong need for horizontal cooperation and concentration on system interoperability. These aspects were pointed out as main challenges for the ESFRI programme and the European Research Area as whole.
These challenges can be meat by
-
cooperation of the RIs on solving common problems - joint activities, reusing technology, to use the synergies across countries and disciplines
-
adoption of common standards and practices
-
professional efficient management of the RIs with explicit governance model determined to sustainability
-
focus on data management, especially accessibility and long-term preservation through horizontal data-services eventually leading to an common European Data Infrastructure
Data's shameful neglect
Research cannot flourish if data are not preserved and made accessible. All concerned must act accordingly. [Nature, 9 September 2009]
For better undestanding the complex e-Infrastructures eco-system can be divided into layers building on top of each other, yielding following stack (with example projects):
Table 1. Layers of the e-Infrastructures eco-system global virtual research communities CLARIN, FLARENET data access (MD-based interoperability) CLARIN, DRIVER, CESSDA, METAFOR simulation and visualisation EUFORIA access management TERENA, eduGAIN computation facilities (supercomputing, Grid) EGEE, DEISA network infrastructures GÉANT, TERENA -
- Global Virtual Research Communities
-
a notion for the organizational structures which already exist and will increasingly emerge in the context of the research infrastructures.
Groups of individuals and organizations not defined by their institutional affiliation, but rather their membership in cross-boundaries projects and research infrastructures.
Figure 1. Virtual communities - sharing commmon layers of the e-Infrastructure eco-system [K. Koski]
![Virtual communities - sharing commmon layers of the e-Infrastructure eco-system [K. Koski]](resources/neeri_helsinki/koski_GlobalVirtualResearchCommunities.png)
- PARADE, Partnership for Accessing Data in Europe, www.csc.fi/english/pages/parade
-
a consortium - a new initiative dedicated to the issues of interoperability of data environments and horizontal cooperation, collaboration across geographical and disciplinary boundaries, with the main goal of common data services.
White Paper: Strategy for a European Data Infrastructure
- e-IRG, e-Infrastructure Reflection Group
-
an advisory body to support the creation of a political, technological and administrative framework for an easy and cost-effective shared use of distributed electronic resources across Europe, by defining and recommending best practices for the pan-European electronic infrastructure efforts.
In spring 2008 the Data Management Task Force (DMTF) was proposed, that shall be concerned with topics: Metadata and Quality, Interoperability, Survey of the existing projects and initiatives. Final Report at fall 2009.
- ERIC, European Research Infrastructure Consortium, ec.europa.eu/research/infrastructures/eric_en.html
-
a new (Aug 2009) legal form, which allows to set up european entities having legal personality recognized in all member states, to facilitate the joint establishment and operation of research facilities of European interest.
There are a number of technical aspects that are common to most of the Research Infrastructures, asking for horizontal collaboration:
-
interoperability
-
persistent identifiers and long term preservation
-
virtual collections
-
technologies for access - authentication, authorization - identity federations
-
employment of Grid and supercomputing technologies
Most of them were discussed in Helsinki and are summarized in the following subsections.
As another way to see this field, Keith Jeffery formulated following seven research challenges arising from the development of topics mentioned above:
- Metadata
-
simple metadata models like DublinCore are thorougly insufficient in the new complex environments, need for metadata related to services, data/information/knowledge, agents: Advanced standardised metadata. (Metadata plays a role in all of the other challenges)
- Management of state
-
detection and maintenance of state across millions of individual nodes, which is not feasible with traditional DB-systems
- Data representativity
-
data structures representing real-world interrelationships, modelling temporal aspect, probability, incomplete information, etc. into fully connected graphs, obsoleting tree-structures or hierarchy, allowing interoperation between different data structures representing a similar real-world domain;
- Data quality, veracity and permanency
-
detection of quality against metadata parameters, provisions for provenance, temporality, etc.
- Trust, security, privacy
-
policies can be declared, enforced and monitored through restrictive metadata
- Management of service levels and quality of service
-
allowing service level negotiation
- System design, development, maintenance and decomissioning
-
based on self-composition, self-managing and adjusting, self-maintaining; mobile code properties
P. Wittenburg, M. Lautenschlager, P. Doorenbosch, K. Jeffery
As already mentioned metadata in the broadest sense as descriptions of resources and entities (data, services but also scientific output, and actors) are crucial aspect in most of the issues covered by all of the research infrastructures: Grids cannot work without metadata on sources, on resources and on users. Standardisation of the interface descriptions for the services is at the core of SOA.
Metadata must have formal syntax and declared semantics to be machine-readable and machine-understandable.
Metadata needs to be open since otherwise no sufficient visibility of resources and tools is achieved, but there are ongoing discussions e.g. due to ethical reasons.
Classification of metadata:
- Schema
-
normative, constraining
- Navigational
-
how to get it
- Associative
-
descriptive, restrictive, supportive
The situation In LR field is, that many (legacy) schemas exist, but the field is seems to converge towards flexible MD frameworks based on an extensible abstract meta-model (semantically) populated with registered well-defined elements. The semantic interoperability shall be achieved by deifning relations between these elements.
Following a few key terms regarding metadata models, but as said the metadata aspect is present in all the other topics as well (In particular a separate section is dedicated to metadata in HLT):
- DRIVER, Digital Repository Infrastructure Vision for European Research, www.driver-repository.eu
-
The main goal is open access to european research material through an operational network and service. The central organisation is responsible for harvesting the MD and providing a centralized access point, the DRIVER Search portal allowing to search 1. mio objects contributed by the associated Institutional Repositories. Institutional Repositories are responsible for creating, maintaining and normalisation of MD, copyright clearance, stable aacess to linked resources, long-term preservation and access. Dublin Core is the base of current metadata model.
- Europeana, www.europeana.eu
-
a multi-lingual online collection of millions of digitized items from European museums, libraries, archives and multi-media collections - access to European Culture
Started in 2005 based on the European Library project, now operational service for integrated access to European national libraries.
It links to 4.6 million digital items: images (paintings, drawings, maps, photos and pictures of museum objects), texts (books, newspapers, letters, diaries and archival papers), sounds (music and spoken word), videos (films, newsreels and TV broadcasts)
Dublin Core is base of current metadata model as the least common denominator for the wealth of different metadata formats used in the different legacy and closed systems. OAI-PMH is used for MD harvesting, OAIS is the reference model for organising the ingest process.
- METAFOR, metaforclimate.eu
-
Develop, deploy, and evaluate a prototype infrastructure, that will allow key data and models to be discovered and compared between distributed digital repositories.
METAFOR shall coordinate the efforts in filling of metadata gaps, mapping to different standards, aggregating the metadata and creating new standards if necessary.
- CIM, Common Information Model
-
standard metadata model building on existing metadata standards to describe climate data and the models and experiments that produced those data.
- enes, European Network for Earth System Modelling, isenes.enes.org
-
A group of ~ 50 member institutions concerned with development and evaluation of state-of-the-art climate and Earth system models, currently active in the FP7 project : IS-ENES.
It is adressing the requirement for pan-European Data Services and interdisciplinary research, currently hampered by heterogeneous data models and problems in model data utilization across disciplines. These shall be overcome by common metadata format (METAFOR/CIM as federated data model), preprocessing of data and help and guidance in model data interpretation.
D. Giaretta, K. Jeffery, M. Piccoli
Preservation is a complex process involving not only bits and formats. The claim has to be made testable, therefore we need to understand the use. It has to be clear what is being preserved, for whom, for how long. Just saying we need "metadata" is too vague. In particular we need information about Representation Information and Designated Community.
Threats:
-
Users may be unable to understand or use the data e.g. the semantics, format or algorithms involved.
-
Lack of sustainable hardware, software or support of computer environment may make the information inaccessible.
-
Evidence may be lost because the origin and authenticity of the data may be uncertain.
-
Access and use restrictions (e.g. Digital Rights Management) may not be respected in the future.
-
Loss of ability to identify the location of data.
-
The current custodian of the data, whether an organisation or project, may cease to exist at some point in the future.
-
The ones we trust to look after the digital holdings may let us down.
-
Metadata is the key!
-
There are some standards for research publications and many standards for research data (by subject discipline), but the research context needs to be captured as well, thus need for advanced standardised metadata (see CERIF)
-
Virtual research environment in which the researcher acts on the body of knowledge and the Information infrastructure which is responsible for the lifecycle (preservation) of the information are orthogonal. The researcher shouldn't have to worry about the information infrastructure
-
Recursion plays an important role: representational information needs to be preserved (and thus represented) as well.
-
Thanks to automated collection, we face a data deluge - constantly growing
-
need for business and governance models to ensure curation is done and access provided
-
(difficult to) estimate cost vs. value of preservation.
One has to take into account: cost of re-collection, cost of lost data/information/knowledge. Also the value could be derived from reasons why the items should be accessible, but science generally remains a public good and the rules of free market do not apply (due to monopolies, scarcity, obligations, etc.), thus costs will have to remain part of the normal funding models of science (subsidise). There is also a moral obligation to preserve.
-
rights also have to be considered: copyright, database right, protect position to sell good or service
-
a study investigating the medium to long term costs to Higher Education Institutions (HEIs) of the preservation of research data [www.jisc.ac.uk/publications/publications/keepingresearchdatasafe.aspx] found following distribution:
-
42% Acquisition and Ingest,
-
23% Archival Storage and Preservation (containing: MD Creation, Bit-stream Preservation, Content preservation)
-
35% Access
-
-
Commercial services - Cloud storage
Amazon S3 = Simple Storage Service and AWS Import/Export (“send your harddisk”) services costs $150-$180 / TB / Month. There are issues with security and trust Amazon being subject to U.S. law. And also these service are anything but "long-term" or "permanent" as they can be terminated by Amazon anytime (with 60 days grace period) as is stated in the terms of use.
So this is quite unsuitable for archival long-term data storage, but could maybe be interesting for a buffering of data for active research during a limited period of time
-
recognise the value of curated information
-
demand e-infrastructures comply
-
expect researchers to comply
-
threshold barrier has to be overcome: the effort of uploading the dataset, inputting metadata(!)
- OAIS, ISO:14721:2003, Open Archival Information System, public.ccsds.org/publications/archive/650x0b1.pdf
-
an ISO reference model, a architectural framework, defined by the Consultative Committee for Space Data Systems (CCSDS) in 2002
- OAIS Archival Information Package (AIP)
-
a concept for identifying a collection of information that can be preserved over a long term.
- SOKUs, Service oriented Knowledge Utilities
-
a vision or concept for Next Generation Grids; "marriage" between SOA and Grid technologies. As the name already says it, they are:
-
Service-oriented - services which may be instantiated and assembled dynamically
-
Knowledge-assisted - or semantic, i.e. the services and the processed content are annotated with machine-processable metadata
-
Utilities - a directly and immediately useable service, with established functionality, performance, etc.
more information in Next Generation Grids Report 2005: www.semanticgrid.org/NGG3
-
- CERIF, Common European Research Information Format, www.eurocris.org/cerif/introduction
-
a standard (EU Recommendation to member states), started in 1987, rework 1997, since 2002 care and custody of CERIF by euroCRIS, last version CERIF2008.
Allows to capture the research context information (modelling entities like project, person, organisational unit), it is fully internationalised, extensible, provides, rich semantics, usable for data exchange, but also for querying hetergeneous distributed environments.
- euroCRIS, Current Research Information Systems, www.eurocris.org
-
professional not-for-profit association of CRIS experts and custodian of CERIF is dedicated to improvement of research information availability
- CASPAR, Cultural, Artistic and Scientific knowledge for Preservation, Access and Retrieval, www.casparpreserves.eu
-
an integrated project co-financed by the EU FP6, started in 2005, aimed to implement, extend, and validate the OAIS reference model, deal with Representation Information and Designated Community, etc.
- PARSE.Insight, Permanent Access to the Records of Science in Europe, www.parse-insight.eu
-
FP7-co-funded project started in 2008, to produce a roadmap and recommendations for developing the e-infrastructure in order to maintain the long-term accessibility and usability of scientific digital information in Europe.
- DSA, Data Seal of Approval, www.datasealofapproval.org
-
Ensure that in the future, research data can still be processed in high-quality and reliable manner, without this entailing new regulations or high costs.
Making data future-proof by ensuring that data sets and metadata meet certain requirements: the 16 DSA quality guidelines.
The DSA is assigned by the DSA Assessment Editorial Board via nominated peer-reviewers. DSA assignment is valid for one year and can be renewed every year.
- Repository Audit and Certification, wiki.digitalrepositoryauditandcertification.org
-
draft standard submitted to CCSDS/ISO to form the basis of an international audit and certification process for digital repositories
![Model of OAIS AIP [nssdc.gsfc.nasa.gov/nssdc_news/dec00/oais.html]](resources/neeri_helsinki/oais_AIP_fig2.gif)
L. Lannom, K. Jeffery, U. Schwardmann, R. Kramer, P. Wittenburg
The main goal of PID systems is to be able to go from object name to current state data. This is achieved by introducing a(nother) level of indirection, so that the name can persist over changes in location and other attributes.
Requirements for the identifiers:
-
not based on any changeable attributes of the entity (location, ownership...)
-
opaque (meaningless)
-
unique
-
should be actionable, (ie provide location, elementary metadata, validity check)
Requirements for the resolution system:
-
reliable (no single point of failure)
-
scalable
-
flexible
-
trusted
-
open architecture
-
transparent
-
persistent
Open topics (which should be determined and agreed on in the infrastructure and not shifted to PID system):
-
granularity
-
fragment addresssing (Template Handle as one possible answer?)
-
different representations, content-negotiation/detection (Handle System Chooseby possible answer?)
- DOI, Digital Object Identifier System, www.doi.org
-
The DOI system is an application of the Handle System with value added (policies, procedures, business-models), in other words Handle System is the underlying resolution technology of the DOI system. The provider and governance body is the International DOI Foundation.
Handle System DOI name prefix prefix = "10.”, e. g.
doi:10.1000/182being the DOI Handbook; DOI resolver: dx.doi.org - EPIC, European Persistant Identier Consortium, pidconsortium.eu
-
-
a new group aimed to setup and maintain a PID service
Partners: GWDG, Germany; CSC, Finland; SARA, Netherland
-
reasons: political independence, DOI is too expensive
-
based on Handle System
-
currently single service available
-
plans: setup mirrors, SSL protocol
-
- Universal Resolver
-
Multiple systems are already running: Handle, Digital Object Identifier (DOI), URN, Archival Resource Key (ARK). These already need to stay forever.
The user shouldn't need to distinguish between the identifiers, thus a kind of resolver resolver will need to be established, which will be able to redirect any PID-request to the correct resolution system. (Optimally this should be integrated in the existing systems.)
Handle System www.handle.net
-
General purpose distributed information system providing Identifier and Resolution Services. Logically a single system, but organizationally and technically distributed and highly scalable; based on open, well-defined interface specifications for the protocol and data model: www.handle.net/rfcs.html
-
The software consists of a Server (Java), Client (Java) , Proxy servlet and a collection of Community software like various helper tools, alternative clients, etc. Version 6.2 was released June 2006 under public license. (There are other implementations (not public) based on the specifications.)
-
To provide the resolution services one has to register as a Resolution Service Provider (RSP) and accept the HS Service Agreement.
-
a PID or "handle" is of the form:
hdl:<prefix>/<sufix>, e.g.:hdl:10.1000/1Every PID can be associated with one or more typed values (IP address, public key, URL)
The prefix is a naming authority handle identifying the LHS responsible for given prefix
used to access the service information that describes the "home" service of the naming authority.
-
resolution mechanism: upon client-request Global Handle Registry resolves the prefix-part of client's request to Service Information, containing information about sites and servers of the responsible naming authority. Client than queries given one server of one of the available sites, which responds with the handle data. All sites in one LHS provide the same replicated set of handles, whereas the servers of one site share the identifiers and resolution requests load evenly.
Figure 3. The 2-level hierarchical architecture and client querying the Global Handle Registry [www.handle.net/lhs.html]
![The 2-level hierarchical architecture and client querying the Global Handle Registry [www.handle.net/lhs.html]](resources/neeri_helsinki/PID_GHR_LHS_hs-3.gif)
-
a web proxy server exists to wrap the resolution in HTTP: hdl.handle.net
-
Template Handles possible: unlimited number of handles can be derived from a registered template, based on rewrite rules
-
multiple resolution: "Chooseby" - allows structured alternatives (with selection criteria) in a single handle value
-
Existing identifier schemes (e.g. ISBN) can be integrated by assigning them a separate prefix and defining rewrite rules.
-
System usage: There are quite a few important users: Library of Congress, IDF(DOI), OECD, DSpace, etc. amounting to over 1000 LHS. More than 210.000 prefixes are assigned, DOI alone manages round 42 mio. handles, plus millions in other prefixes, of which exact number known only to the prefix manager, but overall the amount certainly exceeds 600 million handles. The system processes tens of millions of resolution requests per month.
-
The system is financed mainly through fees: $50 registration fee + $50 annually / per prefix
-
Outlook:
-
Default web-to-handle proxy server system (hdl.handle.net)
-
further Global Mirrors - agreements pending with CNNIC, GWDG
-
creation of a Handle System Board
-
D. Lopez, D. Broeder
Authentication and Authorization Infrastructure is one of the crucial technologies when talking about RI. It allows to "share users and resources" among members of the Identity Federation based on delegation, by establishing a "Trust Domain". So federations are Trust Brokers, where we can distinguish two kinds of trust:
- Technical Trust
-
Trustworthy entity metadata, which assures secure communication between the entities
- Behavioural Trust
-
needs technical trust as necessary basis, but additionaly it needs to be rooted in contractual hand-shakes and adhering to agreed upon policies.
Thus a federation is both a member organisation and a technical infrastructure, embodied by the core middleware (see e.g. Shibboleth) providing the foundation services: messaging (SOAP, REST, XMPP), trust (PKI) and identity (LDAP, PKIX, SAML).
Today there is a growing number of federations (some of them listed here: https://refeds.terena.org/index.php/Federations), which evolved largely independently, based on various technologies.
However the need for putting them together - let's call it "interfederation" or "confederation" - grows. To allow interaction between federations, a further infrastructural layer has to be employed, that a) provides information about individual federations to all the other federations serving as MD aggregator (see Metadata Service), b) translates between the (possibly different) protocols used in the individual federations (see Bridging Elements), c) filters the communication between the federations, applying restrictions and policies agreed upon among the member federations. Although the existing federations use various protocols, there seems to be a fast convergence towards SAML 2.0, which would simplify the federations-interaction, hence foster the creation of interfederations. The foremost initiative in this respect is eduGAIN, which among other activities currently runs a pilot confederation of 15 national and community federations.
The key to authorization is the availability of specific attributes, needed by the Service Provider to decide if the user has the right to access given resources. The required attributes can be different from one Service Provider to another, as well as the attributes made available by the Identity Provider can differ, so again here a need for agreement on the attributes necessary and available. Various schemas have been proposed for management and exchange of the attributes.
| Local Schemas |
| iris-* |
| SCHAC - SCHema for ACademia - extension to eduPerson |
| eduPerson |
| Basic schemas (person, inetOrgPerson, organizationalPerson) |
Current issues:
Future developments [www.switch.ch/aai/support/presentations/opcom-200909/AAI-OpCom-Interfederation.pdf, www.iay.org.uk/blog/2009/05/concepts_and_me.html]:
- Scalable Metadata Exchange
-
Currently the federation metadata is handled largely as one file. With growing federations the metadata will grow. This will require the creation of a Metadata Layer formed by a network of Metadata Aggregators enabling scalable metadata exchange. One steps towards this concept is the Metadata Service in eduGAIN, which acts as a MD Aggregator.
- Metadata Tagging
-
Describe the entity in a way suitable for filtering. Third party asserts that an entity meets some qualification. The
<mdattr:EntityAttributes>element is used. Tags are in use by the UK federation. Again appropriate attributes need to be defined and agreed upon among all participants.
Basic terms:
- IdF, Identity Federation
-
organisational and technical facilities that - by establishing a "Trust Domain" - enable the portability of identity information across autonomous security domains, allowing the users of the individual domain shared access to resources in the federation.
- SP, Service Provider
-
the organisation providing resources in an identity federation
- IdP, Identity Provider
-
the "home" organisation in an identity federation, managing the identity of the user
- PKI, Public key infrastructure
-
a system for encrypted communication, based on asymmetric key algorithms, which allows to communicate secretly withouth the need of secure initial exchange of one or more secret keys (shared secret).
- CA, Certificate Authorities
-
an entity (a trusted third party) that issues digital certificates for use by other parties
- Digital certifcate
-
an electronic document which uses a digital signature to bind together a public key with an identity
- CRL, Certificate Revocation List
-
a published (regularily updated) list of invalid ('revoked') certificates
- SSO, Single-Sign-On
-
a technology in identity federations, enabling the user to access mulitple resources/services in the federation with only one login.
- AAA, Authentication, Authorization (or Access Control) and Accounting
-
1. verifying entities digital identity, 2. determine permission of given entity to access specific resource, 3. tracking of the consumption of network resources by the user.
- ECAM, European Committee for Academic Middleware
-
coordinating activity, proposed as a joint steering committee for TF-EMC2 and TF-Mobility
- REFEDs, Research and Education FEDerations, https://refeds.terena.org/
-
global collaboration among identity federations - coordinating activity essentially on policy issues; aims at collecting, disseminating and (when possible) harmonising the procedures and policies followed by the participating federations
Survey of federations in higher education: https://refeds.terena.org/index.php/Federations
- TACAR, TERENA Academic CA Repository, www.tacar.org
-
trying to solve the problem of how to get appropriate root CA certificates needed by the browsers with TACAR TERENA offers a single authoritative source for certificates and policies - a PKI-based web of trust among the global academic and research community. It has been adopted by the Grid Community - trust repository for the EUGridPMA and the IGTF - and base for GÉANT multi-rooted PKI effort.
- TCS, TERENA certificate services, https://www.terena.org/activities/tcs/
-
allows a variety of digital certificates to be offered to research and education institutions served by participating NRENs, provided by Comodo CA Limited, one of the largest worldwide Certification Authorities.
- eduroam, www.eduroam.org
-
an TERENA-based infrastructure providing secure international roaming service for users in Higher Education in almost whole Europe, Australia and Japan (and selected US organisations). Organisationally a confederation of NRENs based on reciprocal access, it is an show case example of a successful confederation realization, living up to it's slogan: “open your laptop and be online”
However in the current form it only provides authentication, not yet auhorization (or authentication=authorization) and carries also other technical shortcomings (hierarchical trust establishment AND routing of access requests, no dynamic trust establishment, use of shared secrets). The efforts to overcome this limitations run under eduroam-ng and DAMe.
- eduroam-ng
-
next generation of eduroam; after evaluating emerging protocols: Diameter, RadSec and DNSROAM, RadSec shall be introduced; authorization shall be implemented through SAML-based federations. [see DAMe]
- DAMe, Deploying Authorization Mechanisms for Federated Services in the eduroam Architecure, dame.inf.um.es
-
a GÉANT- and TERENA-based project; it's main goal is to define a unified authentication and authorisation system for federated services hosted in the eduroam network. Those federated services can range from network access control to distributed services like Grid computing.
In other words based on eduroam - the user is not only automatically online in a remote institution, but also immediately has access to resources - protected services (subject to authorization of course).
DAMe will build on and integrate: eduroam, Shibboleth, eduGAIN (as the authorisation back-end) and NAS-SAML (an access control approach for AAA environments, to be used to extend eduroam for authorization). Following figure depicts the basic idea: After the user has been authenticated via eduroam (steps 1-3), he is provided with a "SSO-token" required as key for authorization in further interaction (steps 4-8, access to Protected Service).
- perfSONAR, www.perfsonar.net
-
a consortium of organisations, a protocol and a set of software - a SOA infrastructure for network performance monitoring on paths crossing several networks (Multi-Domain Monitoring), necessary in federated environments. Rooted in GÉANT/TERENA, it is based on eduGAIN for AAI
- autoBAHN, Bandwith on Demand
-
a joint research activity (GÉANT2/JRA) for engineering, automating and streamlining the inter-domain setup of guaranteed capacity (Gbps) end-to-end paths; current status: [www.geant2.net/server/show/nav.00d00a008006]
- GEMBus
-
TERENA-based effort: a new approach to infrastructure interoperability; a framework to define, discover, access, and combine network services; federated, multi-domain ESB (Enterprise Service Bus), able to integrate any service within the GÉANT infrastructure, allowing flexible negotiation of service provision capabilities [tnc2009.terena.org/core/getfile.php?file_id=238]
- Shibboleth, shibboleth.internet2.edu
-
open-source AAI/SSO middleware created by Internet2 Middleware Initiative
![DAMe SSO Architecture [dame.inf.um.es/htmldocs/dame_sso.html]](resources/neeri_helsinki/DAMe.SSO.architecture.jpg)
- X.509
-
standard for PKI for SSO and Privilege Management Infrastructure. First issued in 1988 it assumed a strict hierarchical system of CA, currently in version 3 other toplogies are supported (bridges, meshes).
- PKRQP, PKI Resource Query Protocol
-
an Internet protocol used for obtaining information about services associated with a X.509 Certification Authority; It is being developed in the IETF PKIX Work Group, current status: draft [tools.ietf.org/wg/pkix/draft-ietf-pkix-prqp]. Experimental deployment in TACAR planned(?).
- LDAP, Lightweight Data Access Protocol, tools.ietf.org/html/rfc4510
-
an IETF-endorsed widespread application protocol for querying and modifying directory services running over TCP/IP. Diego Lopez proposes it “as the most sensible choice as communication protocol for exchanging identity information”.
- EAP, Extensible Authentication Protocol, tools.ietf.org/html/rfc3748
-
a universal authentication framework frequently used in wireless networks and Point-to-Point connections.
- RADIUS, Remote Authentication Dial In User Service, tools.ietf.org/html/rfc2865, rfc2866
-
a widely deployed AAA protocol; introduced in 1991; using UDP for transport, shared secret encryption and the (insecure) MD5 hashing algorithm are some of the shortcomings leading to RadSec aimed to mitigate those problems.
- RadSec
-
a new (IETF-draft) transport profile for RADIUS packets, providing a reliable transport (by using TCP instead of UDP) and a strong cryptographic security layer (by using TLS over the TCP connection); allows dynamic discovery of authentication servers [tools.ietf.org/html/draft-ietf-radext-radsec-05]
- Diameter
-
full-blown protocol for the Authentication, Authorisation and Accounting; designated successor of RADIUS, however after evaluation in eduroam-ng activities it was concluded not ready for production yet.
- SLCS, Short Lived Credential Service, www.tagpma.org/authn_profiles/slcs
-
service that issues short lived X.509 credentials based upon successful authentication at an Identity Provider. The main advantage compared to "traditional" certificates is the simplified processing.
- SAML 2.0, Security Assertion Markup Language
-
XML-based standard for exchanging authentication and authorization data between security domains; in it's current version SAML 2.0 (ratified as OASIS standard in 2005) it represents a convergence of the existing standards: SAML 1.1, Liberty ID-FF 1.2, and Shibboleth 1.3 [saml.xml.org/]
- XACML, eXtensible Access Control Markup Language
-
an OASIS standard for expressing security policies; a declarative access control policy language implemented in XML [wiki.oasis-open.org/xacml/]
- NAS-SAML, ants.dif.um.es/designs/nas_saml
-
is a network access control approach for AAA infrastructures, allowing to manage the user authentication process and authorisation attributes. It is based on the SAML and XACML standards.
GÉANT Authorisation INfrastructure for the research and education community
www.edugain.org , www.geant2.net/server/show/nav.1912 (JRA5)
eduGAIN is the confederation technology developed by the GÉANT2 project in order to achieve the interconnection of federated Authentication and Authorisation Infrastructures (AAI).
The eduGAIN architecture ensures safe and trustworthy communication between the resource owner (remote domain) and the users home institution (home domain) belonging to different local federations. This is achieved through the Metadata Service (MDS), the Private Key Infrastructure (PKI) and a set of naming conventions for its architecture components.
The eduGAIN technology involves a translation of protocols between the ones used in local AAIs by introducing an abstraction layer provided by the eduGAIN libraries. Secure data transport is ensured by the use of encrypted communication channels between entities. eduGAIN components communicate among each other via SAML.
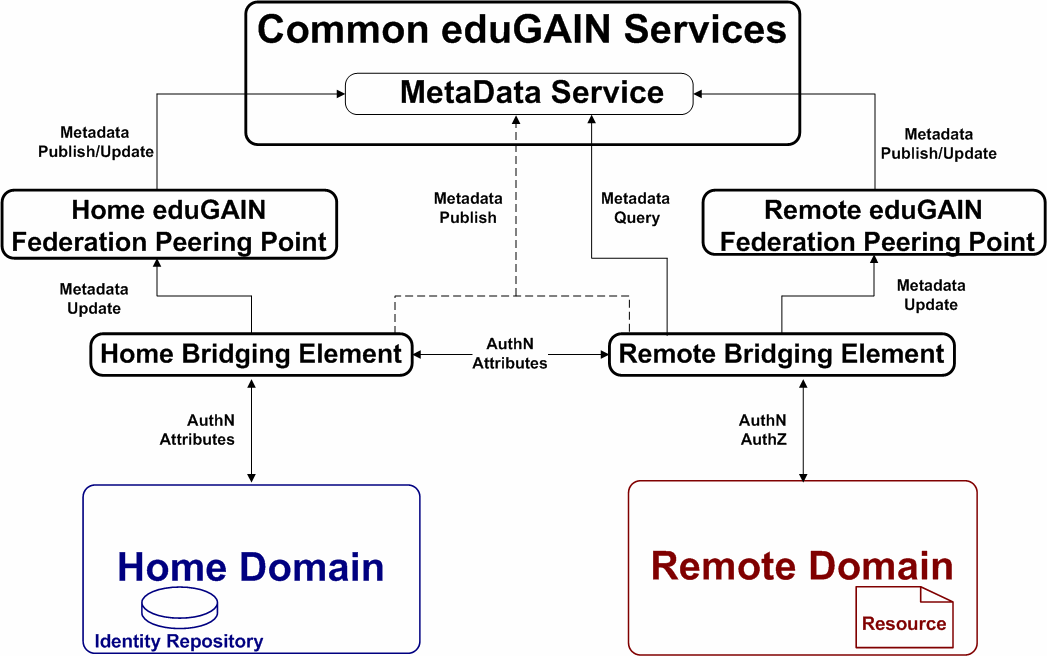
eduGAIN elements:
[www.geant2.net/upload/pdf/GN2-08-130-DJ5-2-3-3_eduGAIN_AAI_CookBook-1.pdf]
- MDS, Metadata Service
-
Metadata Aggregator - a central point where federations publish their metadata, such as location or authentication and authorization mechanisms, to allow other federations (via Bridging Elements) to discover it, hence enable dynamic inter-federation communication. [dame.inf.um.es/htmldocs/dame_sso.html]
SAML 2.0 Metadata specification, must communicate via REST protocol
- BE, Bridging Elements
-
the eduGAIN endpoints. The BEs serve two purposes:
-
they make protocol and attribute conversions (mapping of attributes depending on local definitions) (protocol gateway)
-
they serve as a trusted entity for both the Identity and Service Providers.
So even if all federations can speak one protocol, the BEs are still needed as brokers between the IdP and SP from different federations. Otherwise a full mesh topology would be required, where every IdP and every SP know and communicate directly with each other.
The two communicating entities have to fully trust the BE to behave properly. Via their two components:
HomeandRemotethe BEs stand in as IdP to the local federation's SP and as SP to the local IdP respectively. As such they have to be introduced in the federation as any other SP or IdP.Every federation in a confederation needs at least one BE (normally both and Remote component) either as
- Local Federation Adaptor
-
for whole federation acting as trust aggregator
- Local Adaptor
-
only for one institution or a group, which in practice means, that the already existing local federation software is made eduGAIN-aware
-
- IFEP, Inter-federation endpoint
-
a component in a federation providing direct connection to the confederation, an alternative to BE, or other name for a Local Adaptor BE
- FPP, Federation Peering Points
-
components that serve as a means of publishing metadata about a federation through the MDS. For each federation connected to eduGAIN there is exactly one FPP. It acts as a central administration system wrt the interaction of given federation and the confederation.
- Component Identifiers
-
formal naming conventions for all components in an eduGAIN confederation have to be established. Every components is identified by means of URNs in the
urn:geant:edugain:componentnamespace. - Naming/Identifier Registry, https://registry.edugain.org
-
a service that contains the valid identifiers applicable within the eduGAIN infrastructure. It manages the
urn:geant:edugainnamespace. - eduGAIN Schema
-
attributes exchanged by the eduGAIN components SHALL be in accordance to the SCHAC schema
- eduGAIN truststore
-
a set of PKI Certificate Authorities (CA) created within the project
- eduGAINCA
-
the root CA in the eduGAIN context. At least one will be established and run by the project. It will only issue certificates to other CAs (SCAs).
- eduGAINSCA
-
subordinate CA responsible for issuing certificates for components in a particular branch of the eduGAIN component identifier namespace
- eduGAIN Certificate Policy
-
a document to which the CAs in the truststore must conform to, defining the rules and procedures agreed by the eduGAIN participants to rely on digital public certificates issued to the components of the infrastructure
Different clients - different profiles:
Done so far:
-
pilot confederation with 15 federations and 5 different technologies
-
MDS server mds.edugain.org
-
version 1.0 of the eduGAIN software consisting of
-
Base, Conversion and Validation libraries (Java), eduGAIN API made in Java, providing a set of common libraries for all eduGAIN components
-
simpleSAMLphp (PHP)
-
eduGAINFilter (javax.servlet.filter)
-
Bridging Elements Home and Remote (for Shibboleth); direct use of Shibboleth 2.0 being investigated
-
More material:
- dame.inf.um.es/htmldocs/dame_sso.html
-
Document discussing technicalities of DAMe
- wiki.edugain.org/index.php/Main_Page
-
edugain wiki-page
- www.geant2.net/upload/pdf/GN2-08-130-DJ5-2-3-3_eduGAIN_AAI_CookBook-1.pdf
-
good overview of eduGAIN/confederation, among others the section "A Checklist for Connecting to eduGAIN" (2007-04-24)
- wiki.edugain.org/index.php/File:GN2-08-081_eduGAIN_Profiles_and_Implementation_Guidelines_1.0.doc
-
eduGAIN profiles and implementation guidelines
- www.geant2.net/upload/pdf/GN2-07-024-DJ5-2-2-2-GEANT2_AAI_Architecture_And_Design.pdf
-
GEANT2 deliverable: AAI Architecture and Design
Outlook:
-
Support for dynamic metadata
-
Enhance non-web profiles - Relayed-SAML assertions
-
Support for additional attribute authorities, a bridge with VO management systems
-
Support for user-centric identity models
-
Formal service definition
-
Composable Network Services, see GEMBus
CLARIN will result in a Service Provider (SP) organization offering Language Resources in its broadest sense, tools & web-services.
CLARIN has become an official eduGAIN (GN3/SA3) use case
CLARIN AAI scenarios:
- SSO with a web-browser
-
corresponds to the default WebSSO-profile in eduGAIN
this the default scenario best supported by current AAI
- SSO with a locally installed application
-
corresponds to the UbC-profile in eduGAIN
one considered solution (use of X.509 certificates obtained via SLCS) is being evaluated within the Dutch BiG-Grid project
- Delegation with a web application
-
corresponds(?) to the WE-profile in eduGAIN
- Delegation in a workflow systems using web-services
-
corresponds to the AC-profile in eduGAIN, investigated solutions WS Security (security token, X.509, SAML assertion, ...). No implementation is planned in the preparatory phase.
In order to fulfill CLARIN EU objectives for 2009 a fast path is needed (CLARIN cannot wait for the eduGAIN consolidation), thus a high-priority short-term objective is creation of a Demo of federated identity and SSO access by end 2009 with following parameters:
-
Users with different home organizations in EU
-
3 Federations participating: HAKA [.fi], DFN-AAI [.de], SurfFed [.nl]
-
Representative set of CLARIN SPs in EU:
BBAW, IDS, INL, MPI Psyl, CSC
-
Can be quick &dirty
-
SPs will need to harvest IdF metadata and become member of all IdFs
-
all participants use SAML 2.0, ePPN will be the only required attribute
Long term objectives - "marriage" with eduGAIN:
-
Rely on user’s home organization membership of national IdFs for establishing trust relations with the SPs
-
Establish a CLARIN SP organization as a legal entity able to sign contracts where needed (national IdFs)
-
The CLARIN SPs become members of their national IdFs
-
Rely on the eduGain confederation to provide the trust between the national IdFs
Europe should avoid separate sets of CAs. [Bob Jones]
-
Agree on accepted set of user attributes that should be provided by all IdPs involved
-
Try to harmonize EULAs
P. Öster, B. Jones, J. Reetz, K. Jeffery
The Grid vision
The user can interact with the Grid environment inteligently, the access to data/information/knowledge, computation and instrumentation/detectors is provided transparently only by means of MD.
The end-user clarifies a request using a device, the environment proposes a deal to satisfy the request (which may or may not involve money), the user accepts or rejects the deal.
For this we would need better: representativity, expressivity, resilience, dynamic flexibility. [Jeffery]
While there are a few Grids in operation all over the world - and probably the world's largest EGEE in Europe - used increasingly extensively by "hard-sciences", there seems to be a certain reservation in the area of Humanities and Social Sciences to enter the world of Grid computing. Of course one has to take into that the amount of data in "soft sciences" (HSS) "will always be" order of magnitude smaller than the one in "hard sciences" (Physics, Bioinformatics, Environmental science) - although it keeps growing at approx. the same rates - and the nature and usage pattern of this data is somewhat different. But there seems to be a need for action wrt to accessbility [PARADE_WP] from the side of the Grid-community and a need for more "courage" on the side of HSS.
Because, while there is perhaps not such a strong urge for computing power, with data-services (persistent storage) and other features (SSO, Workflows,...), these two communities have enough topics in common to collaborate on, the Grid community seeming to have already some good answers, of which CLARIN and HSS community in general could take advantage.
Some key terms (next to EGEE, EGI, and DEISA, which are covered in separate subchapters):
- GEANT, www.geant.net
-
high-bandwidth, academic network infrastructure and related services serving Europe’s research and education community, carried by national NRENs
- OGSA, Open Grid Services Architecture, www.globus.org/ogsa
-
an architecture for a service-oriented grid computing environment, developed within the Global Grid Forum (GGF)
J. Reetz
DEISA is rooted in EU FP6, the follow-up DEISA2 in FP7.
FP7 objective: Establishing a persistent European HPC ecosystem that integrates national (tier-1) HPC centres and new large European Petascale (tier-0) centres.
DEISA2 objective: Consolidate the existing DEISA HPC infrastructure and services and deliver a turnkey ready operational solution for the future European HPC ecosystem
Federated operation of the EU HPC infrastructure with rather smaller centers (15 partners) with dedicated user communities.
Human based operation with strong interaction - communication is important (Central Trouble Ticket System, careful documentation of policies, documenting meetings and agreements, collaborative workspaces (e.g. configuration-wiki), etc.)
Each site has following departements constituting a Virtual European Supercomputing Center:
- Applications
-
-
DECI calls
-
coordinating peer reviews
-
Application enabling
-
Benchmarking
-
- Technologies
-
scouting, identifying, evaluating of relevant technologies; upgrading services, planning sub-structure
- Operations
-
-
operating and monitoring of the infrastructure and services
-
Adopting new technologies from Technologies
-
Coordinating the (daily) operation with Applications
-
Change Management
-
Operational security
-
Furthermore there is Technical Coordinator mediating between the departments.
Site deputies are responsible for individual sites and Task leaders responsible horizontally for every service category (Network, Data, Computing, User, etc.). This yields the Federated Operation matrix of Site deputies and Task leaders
![Federated Operation matrix [J. Reetz: DEISA slides, s. 25]](resources/neeri_helsinki/DEISA_federated_operation.png)
-
> 1PF aggregated peak performance
-
highly performant continental global file system (based on GEANT2: sso, gsi-ssh)
-
DEISA common production environment on top of different software environments
-
Project and Community related management information is stored in the Project Management Data Base used by the DEISA User Administration System. No identity federation.
-
Each project has an administrative DEISA Home Site and is mapped to one or more Execution Sites
| User access via Internet (Administration Home Site, Unicore, gridFTP) |
| single sign-on based on X.509 'Grid' certificates |
| DEISA Common Production Environment |
| Different software environments |
| Different Supercomputers |
| Dedicated 10 Gb/s network - via GEANT2 |
| DEISA continental global file system |
- DEISA Extreme Computing Initiative, DECI
-
yearly call for proposals
2009: 50 proposals accepted - 60 mio core-h granted
+ 12 mio core-h granted to 7 Virtual Scientific Communities (e.g. EUFORIA)
-
Global Data Management (global file-system: IBM GPFS)
-
high performance tranfers of large data sets (gridFTP)
-
Monitoring Services
-
User Administration (AAA service)
Common AAA (common project and user administration)
-
Global Project and Resource Allocation Management
-
User- System-related Operational Infrastructure Global App Support (Grid-enabling of user applications needs refactoring the code!)
Flagship Grid infrastructure project operates a Grid infrastructure in production! Arguably world's largest Grid.
In current third phase of EGEE the focus is on migration from a project-based model to a sustainable federated infrastructure based on National Grid Initiatives: EGI - European Grid Initiative, web.eu-egi.eu
EGEE/EGI provides:
- Infrastructure operation
-
based in EU with sites in Asia and US, largest computing Grid on the planet. Currently round 200 VO (with round 14,000 registered users) are using the EGEE infrastructure, more numbers: project.eu-egee.org/index.php?id=417
- Middleware
-
gLite - open source, implements a service-oriented architecture that virtualises resources
- Support for Workflows
-
multiple workflow managers supported: WMS (part of gLite) GridWay (part of RESPECT) Kepler, Taverna
- Extendable monitoring infrastructure
-
Based on NAGIOS widely used and extendable open source monitoring toolkit
- User Support
-
Managed process from first contact through to production usage
The foremost "user" (and co-provider) of EGEE is WLCG (Worldwide LHC Computing Grid). Actually EGEE owes it's existence to large extent the need for processing the huge amounts of data coming from LCH@CERN (15PB/y). Besides EGEE WLCG depends on the resources of OSG, the Open Science Grid based in US [www.opensciencegrid.org/] .
The WLCG structure is organized in tiers:
- Tier-0 (CERN)
-
Data recording, initial data reconstruction, data distribution
- Tier-1 (11 centres)
-
Permanent storage, re-processing analysis
- Tier-2 (~130 centres)
-
Simulation, end-user analysis
Some of the components of EGEE:
- AMGA, ARDA Metadata Grid Application, amga.web.cern.ch/amga
-
Metadata Catalogue of EGEE’s gLite Middleware; main concerns: scalability, performance, fault-tolerance, support for hierarchical collections, security; no support for PID yet, using Logical File Name
- ROC, Regional Operations Centre
-
these provides Help Desk facilities, register sites and manage and support the deployment of gLite middleware on sites, etc.
- VOMS, Virtual Organization Membership Service
-
a system for managing authorization data within multi-institutional collaborations
- gLite, glite.web.cern.ch/glite
-
middleware for Grid computing, created as part of the EGEE project
- gCube, www.gcube-system.org
-
a feature full platform for distributed hosting, management and retrieval of data and information
The key added value of Grid infrastructures is a framework for collaboration [B. Jones]
Recommendations:
-
Consider ALL infrastructures(production Grids, supercomputers, commercial cloud systems, volunteer Grid, network etc.) as a combined e-Infrastructure ecosystem, ie don't specialize on any one system
-
Specialised Support Centres (SSCs) are the means of interaction with user communities
-
Humanities SSC foreseen in ROSCOE project proposal
-
Need to identify clear contact points between the ESFRI projects and e-Infrastructures
-
CLAIRN A-Center rough equivalent of EGEE Regional Operations Centres (ROC)
-
build a matrix of requirements and initiatitves - as a base for collaboration among ESFRI projects and between ESFRI projects and e-Infrastructures
-
Single sign-on
-
Persistent Storage
-
Global
-
Workflows
-
Virtual organisation
-
- Service Level Agreement, https://edms.cern.ch/file/860386/0.7/EGEE-ROC-Site-SLA-v1.6.pdf
-
an example of SLA between Regional Operations Centres (ROCs) and Resource Centers
Summarizing: EGEE is willing to help and integrate CLARIN and SSH in general, but we are rather on the start of a long way here. The huge data and tools heterogenity in LRT (and SSH) seems to be one inhibiting factor (all this would need to be "gridified"), together with the relatively small overall amounts of data and processing compared to hard sciences. On the other hand the production quality features (support for SSO, persistent storage, workflows, etc.) provided by the Grid infrastructures match our needs and sound appealing.
In any case it is not be expected that CLARIN will "run completely in a Grid", raising the question if and on which topics a selective cooperation is possible.
K. Jeffery
The need for mandatory open access, to all products of publicly funded research was claimed multiple times. The main three arguments being:
-
financed by public money
-
the visibility of research - public and professional audience shall see, what has been done
-
encouraging further research - readily available results, allow new research be based on those
-
significantly rises the citation index (one experience being 300%!)
- www.oecd.org/dataoecd/9/61/38500813.pdf
-
a OECD guideline (2007) regarding principles for Access to Reseach Data from Public Funding
M. Salokannel
Directive 'Copyright in the Information Society' harmonized the exclusive rights but gave only a list of possible exceptions to copyright, thus providing the maximum but not minimum level of exceptions, giving leeway to member states regarding limitations and exceptions, which leads to huge differencies among individual the member states.
On the other hand the 'Green Paper: Copyright in the Knowledge Economy' is a consultation as to whether the current mode of harmonizing copyright exceptions is feasible in the on-line environment. Among other findings it proposes that the exception should be made mandatory and what should the scope of such exception be.
In a situation like CLARIN, where the user may access materials from different member states, there is thus a clear need for mandatory pan-European exception for the free research use of copyrighted works and as one important outcome of the whole event a memorandum was formulated adressed to EU legislatures. The formulation of the 'NEERI message' was described as a delicate balancing act, mainly because of the risk of alienating the copyright holders. In it's current formulation it includes two main points:
-
"free use of copyrighted works for academic purposes"
-
"not unreasonably prejudice the legitimate interest of the right-holders"
S. Borg
Council of European Social Science Data Archives (established in 1976) - provides access gateways to important social science data materials and to national collections through data exchange agreements.
In recent years CESSDA has developed resource discovery and data management and access tools, including Nesstar and multilingual resource discovery metadata tools.
The aim of the current effort is the creation of a single integrated system, using a common set of protocols and procedures. For this purpose a coordinating central body is necessary undertaking administrative duties across the network as well as developing common standards, technical platforms and middleware to be applied across the membership. The ESFRI project CESSDA PPP aims to constitute such a new coordinating and administrative body CESSDA ERIC, an independent legal entity recognised in international law and under-pinned by stable and long-term funding from national governments.
The combination of the integrated system with the new administrative body will allow further evolvement of this RI, facilitating the research, teaching and learning in SSH within ERA.
N. Calzolari
Nicoletta Calzolari postulated that the degree of standardization can be seen as an indicator of the maturity of an area and presented the Lexical Markup Framework (LMF) standard also as an example.
The ultimate merits of standardisation:
-
create a coherent market, which is necessary for any large scale strategic programme
-
avoid duplicating work, moreover possibly creating incompatible systems
-
avoid reinventing basic knowledge, reuse existing resources, profit from synergies, concentrate on innovative areas
This is achieved by applying standards to ensure:
-
interoperability of systems (crucial for workflows)
-
reusability and integrability of components in LR infrastructures
-
training, "gold standards" for evaluation campaigns
-
evaluation and validation based on agreed criteria
-
production of mature HLT applications (out of prototypes)
Important methodological principles:
-
discover maximal set of basic notions
-
granularity
-
allow redundancy (edited union of existing lexicons/models)
-
modular, layered, hierarchical structure
-
allow underspecification
There is trade-off between interoperability and variability.
The approach is generally moving towards metadata frameworks based on an abstract meta-model populated with Data Categories as the basic well-defined building elements. This allows flexibility and modularity while keeping the overall system coherent and integer.
Outlook:
- LREC2010 Map, www.lrec-conf.org/lrec2010/?LREC2010-Map-of-Language-Resources
-
Map of Language Resources, Technologies and Evaluation to be contributed by all LREC participants, to be disclosed on LREC2010. A instrument to monitor the field as one step towards very broad community-built Open Resource Infrastructure.
N. Calzolari, M. Kemps-Snijders, www.lexicalmarkupframework.org
-
ISO standardised (ISO-24613:2008) model for representing machine readable lexica
-
based on MILE - Multilingual ISLE Lexical Entry but incorporates a long history of initiatives and standards (Grosseto Workshop 1985, ACQUILEX, MULTILEX, GENELEX, NERC, ET-7, ET-10, DELIS)
-
designed to accomodate different models of lexical representation (including WordNet, EDR and PAROLE lexicons)
-
defined as an abstract high-level meta-model (ISO24613) combined (to be populated) with data categories from the DCRegistry
ISOprofiles a library of ready-to-use packages that can be combined in the applications
-
modular framework complying with UML modelling principles - Core Package with extensions - allows the basic structure (Lexical Resource / Lexical Entry / Lemma, Form, Sense) to be extended with links to synsets, cross-lingual relations, etc.
-
Lexical Classes (defined in LMF) are the main building blocks of the lexical architecture
-
Lexical Objects represent the notions used in lexical entries (to be defined in ISOCat?). These are collected in the LMF library with structural relations defined among them.
Outlook, working towards:
-
Open Distributed Lexical Infrastructure
-
Lexical Information Servers (for multiple acces to lexical information repositories)
-
from (static) LR to (dynamic, distributed) Language Services
-
Lexical Web, Content Interoperability and Semantic Web
-
LexInfo: building on LMF as a core, develop a model which "subsumes" LingInfo and LexOnto for flexibly associating linguistic information to ontologies [Buitelaar, Cimiano, Haase, Sintek 2009]
LingInfo: modeling morphosyntatic decomposition of (complex) terms [Buitelaar et al. 2006]
LexOnto: capturing syntactic behaviour and syntax-semantics links [Cimiano et al. 2007]
Marc Kemps-Snijders besides discussing implementation issues of LMF, also presented a few applications based on LMF:
- Lexus
-
lexicon content editor (based on LMF tree structure)
- ViCos
-
visualize conceptual space: relations between (parts of) lexical entries and between fragments
- Annex
-
display of annotated media files (ELAN), for example by directly linking from lexical entries in Lexus
A. Witt, A. Przepiórkowski, T. Schmidt
Various emerging and already established annotation models in the domain of Language Resources were presented and discussed:
- LAF, ISO 24612, Linguistic Annotation Format
-
[Ide and Romary, 2004, 2006] developed within ISO TC37 SC4
a general framework for representing annotations, specification of an abstract model for annotations instantiated/serialized by a XML stand-off pivot format.
The underlying model is directed graph of annotations, labeld with feature structures on vertices or edges. Nodes are spans in primary data or other annotations
- GrAF, Graph Annotation Format, www.cs.vassar.edu/~ide/papers/LAW.pdf
-
XML serialization of the generic graph structure of linguistic annotations described by LAF
- AG, Annotation Graph
-
an efficient and expressive data model for linguistic annotations of time-series data [Bird, Liberman arxiv.org/abs/cs/0010033]
Annotation Graph Toolkit: agtk.sourceforge.net
- MAF, ISO 24611, Morphosyntactic Annotation Fromat, www.tc37sc4.org/new_doc/ISO_TC_37-4_N225_CD_MAF.pdf
-
defines 2 levels of structuring: tokens (segments of text) and wordforms
- TEI, Text-Encoding Initiative, www.tei-c.org
-
widespread format for encoding texts (since 1994), very expressive, very complex.
Adam Przepiórkowski proposed, that any standard can be expressed in TEI(P5).
- XCES, Corpus Encoding Standard for XML, www.xces.org
-
instantiation and adaption of TEI(P4)
de-facto standard, no documentation [A. Przepiórkowski]
Thomas Schmidt presented a collaborative effort to establish interoperability among various tools for annotation and transcription of time-based multimodal data. A multitude of tools exist with own formats: ANVIL, Praat, EXMARaLDA, ELAN, TASX-Annotator, MacVisSTA, Transformer, Theme, etc. These are used for study of: multimodal behaviour, phonetic analysis, multi-party conversation, transcription, but also language acquisition, dialectology and multi-layer annotation of written texts. The task was to identify a common denominator of and the differences between the native formats and based on this try to define a common exchange format, to be based on AG XML format.
S. E. Wright, M. Windhouwer, E. Hinrichs, J. Odijk, P. Wittenburg
The focus in the according session was on ISOcat, the Data Category Registry and related issues.
- Data Category
-
-
an elementary descriptor in a linguistic structure or an annotation scheme
-
both data fields and enumerated domain values are treated as Data Category
-
Data Category Types: open, closed, constrained, simple
-
each DC has an administrative Persistent Identifier, by which it can be referenced (e.g. in schemata of linguistic resources)
-
- Data Category Registry
-
set of data categories to be used as a reference for the definition of linguistic annotation schemes or any other formats used in the area of language resources
- ISO 12620:2009
-
ISO standard providing a framework (data model and administration procedures) for defining data categories, in particular defining the standardization process.
Data model consists of 3 main parts: Administrative (to keep track of standardization workflow), Descriptive (information for working language) and Linguistic (conceptual domain of object language)
- ISOcat, www.isocat.org
-
-
a Data Category Registry - a reference implementation of the standard for "defining widely accepted linguistic concepts"
-
to support the reusability, integratability, and interoperability of data
-
modelled as a segmented aggregate ("garlic") with standardization core and many DC Selection segments
-
used not only for referencing, but actively for administration of the data categories in the process of standardization, thus also important as a social network or collaboration framework for work on the definitions of DCs and overall structure of DCR.
-
to be used by different thematic domains and different communities of practice within a given domain, to come to a broadest-possible consensus on definitions and cross-domain reuse.
-
problems (partly legacy from predecessor system: syntax):
-
incorrect spellings, definitions, examples
-
multiple entries for seamingly one concept, often just other spelling
-
definitions not strict enough - need for more rigid descriptions
-
conflicting definitions, ...
-
-
To combat these problems guidelines were defined: www.isocat.org/manual/DCRGuidelines.pdf. Furthermore it is necessary to provide an appropriate social networking environment & technical features like peer-reviewing, wiki and forum add-ons, internal messaging system, etc.
-
- DCIF XML, DataCategory Interchange Format in XML
-
XML serialization format of the data model of DCR used in ISOcat for export/exchange
- Relation Registry
-
a mechanism (separate from DCR) for storing (user-specific) relations between concepts (referenced from DCR by PID). This will allow for defining primarily simple relations like equivalence, enabling searching over hetergenous vocabularies (semantic interoperability). In a second step this should also build a base for incorporating ontologies and taxonomies on top of data categories.
No existing solutions yet, however a corresponding component is for example being planned in CMDI.
- Language Codes
-
seamingly simple problem of defining the language of a resource, but much ambiguity in the usage (different names for the same thing and same name for different).
This is also reflected in standardization process. Currently: ISO 639-3:2007 codes for the representation of names of languages (~ 6000).
It has shortcomings and is not accepted in large areas of the world (notably South America), so there are ongoing efforts in ISO for new standards (ISO 639-4/5/6). But ISO 639-3 is there and is applicable/unproblematic in many scenarios so use it wherever possible! Especially provide it to MD-editors (integrate in the UI, one example being IMDI)!
Erhard Hinrichs discussed the relation between "widely accepted linguistic concepts" and the Data Categories defined in ISOcat based on the example of PoS tagsets, concluding that we need both the categories of de-facto standards registered in ISOcat and also these categories mapped onto the ISOcat categories.
P. Wittenburg, M. Kemps-Snijders, D. Broeder, D. Van Uytvanck
Various activities in CLARIN were presented. See also chapters: AAI in CLARIN and CLARIN in Grid.
The need for show cases, for results, that can be presented to funding agencies and other relevant third parties, gave rise to two special efforts (VLW and EDC), prototypically illustrating the future capabilities of CLARIN:
- VLW, Virtual Language World, www.clarin.eu/vlw
-
a portal for language resources an technology compiled from of existing Language Resource Collections (OLAC, IMDI, CLARIN LR Inventory, ...). It provides a facetted browser for the metadata records, a geographical representation (GIS overlay) for the distribution of resources
- EDC, European Demo Case
-
A specific task, with the aim to provide an early prototype based on some of defined use cases, demonstrating the main aspects of CLARIN: distributed resources, distributed collaboration.
Basically it shall be a distributed combined metadata and content search over mulitple written corpora, where the user can first narrow down the resources (corpora) to search in by means of metadata filtering and then issue a content query on this resource selection. The system has to be able to translate the user query into the dialects of the individual hetergeneous corpora and merge the partial results into one response then presented to the user.
Where possible it shall already make use of emerging building blocks of CLARIN, like
Central Metadata Repositoryor theMDSearchcomponent and also build on existing resources of CLARIN members, both the language resources (the corpora) and the tools (the various corpus search engines).The planned release is in autumn 2010, with partial solutions (
MDSearch) probably available earlier. - WebServices Profile Matching
-
Volker Boehlke presented a prototype of a workflow system, allowing to chain web services, based on the input-output format description.
This is a good example of the bottom-up approach applied by (mainly german - D-SPIN) members involved in the web services / workflow system track.
- CMDI, CLARIN MetaData Infrastructure
-
the central machinery of CLARIN in construction (more information about CMDI e.g. in clarin_technical (in german)). Daan Broeder presented a broad overview and outlined the current developments: the implementation of the
Component Registryhas started, the performance of the foreseen metadata repository (XML-DB: eXist) is being tested.First (basic complete) version is expected 3rd quarter 2010.
- Test component XML toolkit, www.clarin.eu/wp2/wg-24/wg-24-documents/component-xml-toolkit
-
first building block of CMDI, allowing to construct CMDI MD-components. In the first step IMDI and OLAC schemas have been mapped to CMDI component specifications.