Abstract
This is a description of the structure and usage of the corpus query system Xaira (as of version: 1.22).
A quote from the home-page
Xaira is the current name for a new version of SARA, the text searching software originally developed at OUCS [Oxford University Computing Services] for use with the British National Corpus. This new version has been entirely re-written as a general purpose XML search engine, which will operate on any corpus of well-formed XML documents. It is however best used with TEI-conformant documents.
Xaira has full Unicode support. This means you can use it to search and display text in any language, provided you have a suitable Unicode font installed on your system.
At the heart of Xaira is the Xaira Object Model. This defines a range of objects and methods for representing and searching large amounts of linguistic data. The Xaira Server program implements this model. The Xaira Indexer program creates platform-independent indexes from collections of XML documents for use by the Server. Both these Xaira components can be deployed on any platform.
Client programs can access a Xaira server using a close-coupled API such as that used by the Windows client (which is written in C++), or via XMLRPC or SOAP. We provide a fully-featured client for Windows, and simpler demonstration clients written in Java and in PHP.
All versions of Xaira are now distributed free of charge under the GNU General Public Licence.
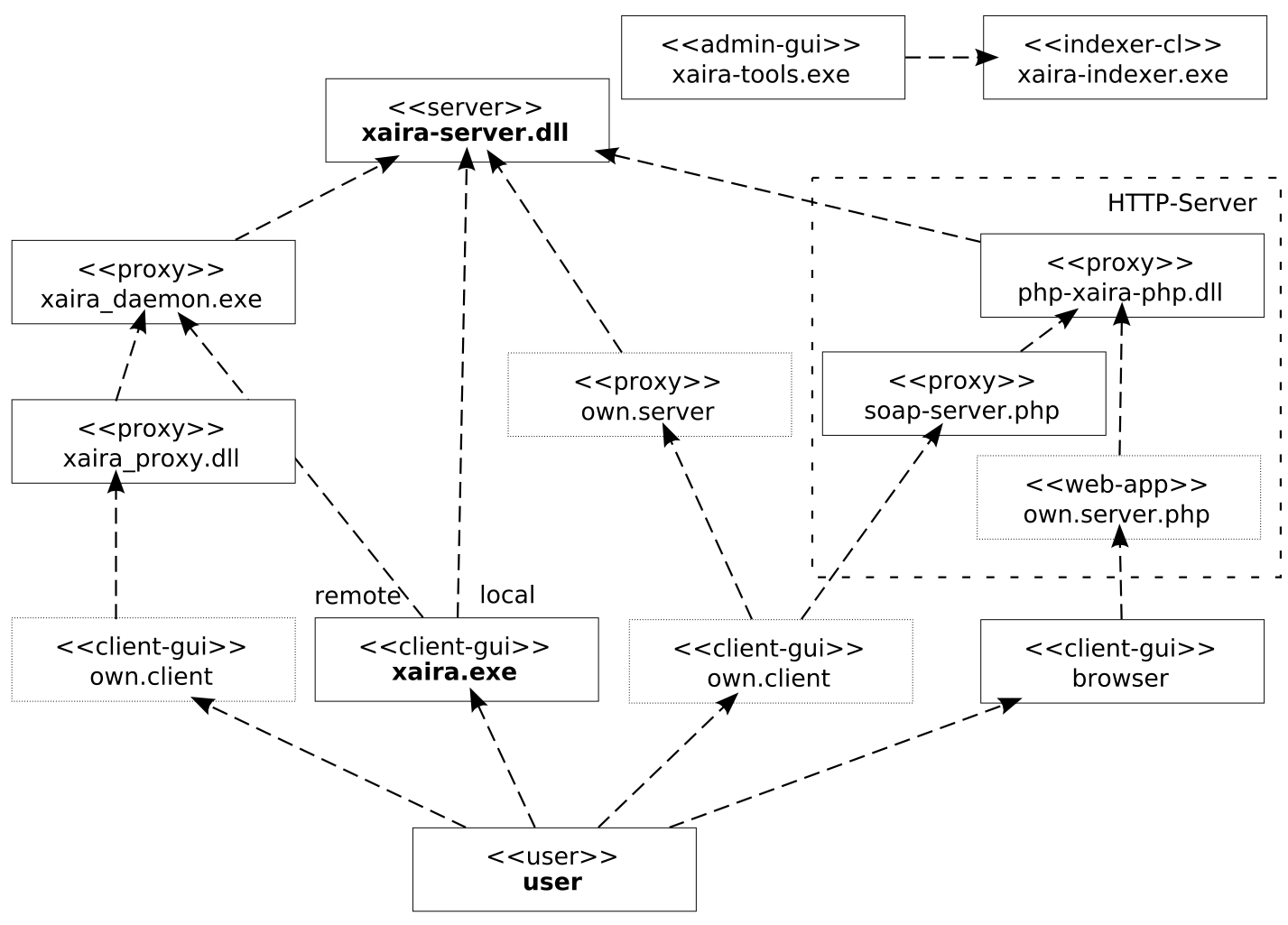
A short description of the xaira-native components:
- xaira-server.dll
the heart of the system, library implements the
Xaira object model- xaira-indexer.exe
command-line tool which creates the corpus indices
- xaira-tools.exe
a graphical client for administrating the corpus (indexing, metadata)
- xaira.exe
sample windows client for querying with full functionality
when running remotely,
xaira_daemon.exeserves as the server- xaira_daemon.exe
this is the server in a client-server mode
command-line tool
- xaira_proxy.dll
proxy mediates the communication between client and server, when Xaira is used within own client-application
Following a diagram depicting the concepts and relations between them used in the Xaira.
Note
This is an unofficial information produced by me, so it may be erroneous.
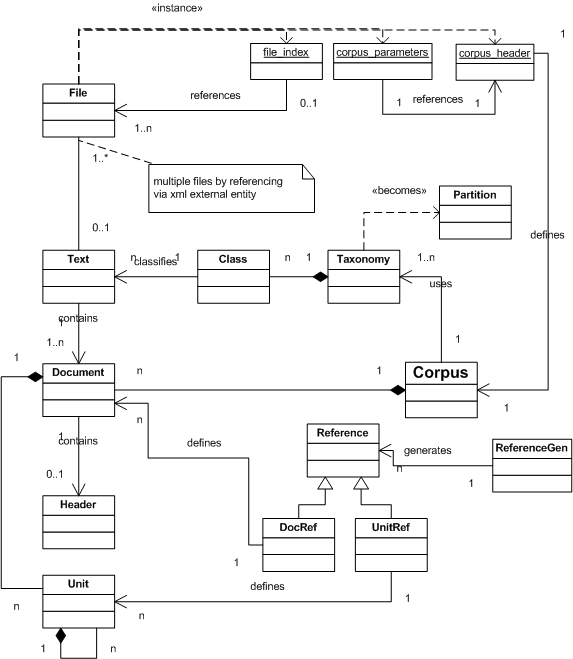
A description of some of the concepts:
- References
define a hierarchy of parts of texts (documents and units).
These are used, when retrieving the context-text for the hit. Following rules apply:
- 0:document/1-n:units
level 0 always defines document
there can be multiple further levels defining smaller units of the texts/documents.
- n<m => |n-unit|>|m-unit|
the higher the level, the smaller should be the size of the unit
- default: 0:file/1:line
by default one file is one document and the one basic unit is line
- file only 0:
file can only define document
- if line, only: 0:file/1:line
if a unit is defined as line only the combination file and line is allowed
All it needs to define a corpus is following 3 files:
- file_index.xml
lists the files which contain the corpus texts
<file_index> <file>FK-01/FK-01-002_n0017.xml</file> <file>FK-01/FK-01-002_n0030.xml</file> ... </file_index>
- corpus_parameters.xml
contains mainly paths to files and directories, which xaira needs to run properly
produced by
Xaira-Tools.menu:Tools/Parameter file<corpus_parameters> <parameter name="etcpath">etc</parameter> <parameter name="name">ch_test2</parameter> <parameter name="textpath">texts</parameter> <parameter name="indexpath">index</parameter> <parameter name="headerpath">corpus_header.xml</parameter> <parameter name="sourcepath">source</parameter> <parameter name="bibpath">bib.xml</parameter> <parameter name="validate">on</parameter> <parameter name="grammarcache">off</parameter> </corpus_parameters>
- corpus_header.xml
contains all the settings and metadata of the corpus: references, additional keys, taxonomies etc.
the structure of the document is quite complex, plus it stores automatic and manual settings
produced by
Xaira-Tools.menu:Tools/Make Header
So one could define the corpus in any text-editor and run the
indexer on the command-line, but mainly at the beginning it is advisable
to edit the settings via the xaira-tools.exe,
although this is also not without issues:
Note
If the corpus consists of very many files (>>10.000) the
dialogue for defining and selecting the texts gets quite busy and
slow. In this case it is better to produce the
file_index.xml "by hand" (eg via a perl-script)
and put it in the ./etc directory, where the apps
of the xaira-suite await it.
Note
When creating a new corpus in xaira-tools 1.21
or 1.22 the
xaira-indexer crashes [issue in the mailing-list]. The
problem is a section in the corpus_header.xml
which the xaira-indexer awaits and crashes when
missing but the xaira-tools does not add (if it
would be empty). [resolution of the
issue]
There are further files, which are "interesting":
- <corpus-name>.xcorpus
serves to identify a corpus in client
it is normally produced by Xaira-Tools.menu:Tools/XCorpus file, but as it is in xml-format, it can be edited manually (if you know what you are doing)
in client-server mode it stores the connection configuration (server-address + port)
- index/xgrammar.xml
information about the corpus: xml-elements and their frequency internal, but readable, possibly useful
For Windows binaries are available in cvs-repository with MSI-installer, straight-forward install. Sources to be build for other plattforms available as well.
Following are the steps, for creation of a new corpus using the
xaira-tools.
Start new corpus
Select texts - defined in the
file_index.xmlParse files
Make header
Define additional keys - traditionally
posandlemmaDefine references (units of the texts)
Define taxonomies
Make corpus file
.xcorpus- needed as identificator for the clientRun indexer
Run test query
Once you have created your corpus, normally you would only do steps 2. and 9., ie change the files-selection and re-index.
The most low-level way to define taxonomonies is to define them
in the corpus_header with following
syntax:
<classDecl>
<taxonomy xml:id="Categories"><!-- Categories taxonomy -->
<category xml:id="cat1"><catDesc>Sachtext</catDesc></category>
<category xml:id="cat2"><catDesc>Gebrauchstext</catDesc></category>
<category xml:id="cat3"><catDesc>Belletristik</catDesc></category>
<category xml:id="cat4"><catDesc>journalistischer Text</catDesc></category>
</taxonomy>
<taxonomy xml:id="Domain"><!-- Domain taxonomy -->
<category xml:id="dom26"><catDesc>26. Anthropologie</catDesc></category>
<category xml:id="dom33"><catDesc>33. Hauswirtschaft, Körperpflege, Mode, Kleidung</catDesc></category>
</taxonomy>
</classDecl>And an appropriate "tag" in the text(-header):
<catRef target="cat1 dom26"/>
In Xaira Queries are defined in xml: CQL. Here
is a description of the
CQL-syntax.
The CQL is very user-unfriendly, thus in the xaira-client for every type of the query an appropriate dialogue is available:
- Word
looks for lemmas. by default (if no lemmatisation scheme is available) every wordform is its own lemma.
- Pattern
regexp in word-index, ie only for one word
- AdditionalKey
possibility to search for attributes, eg pos-tagging
- Phrase
more words, max. 200 chars, anyword-wildcard: ‘_’
- XML
provides a list of elements and attributes, searches for elements start, end-tag, and attributes
- QueryBuilder
graphical, combines all other for complex queries join either by Next, Not-Next, One-Way or Two-Way, scope can be defined for the match to be within # words or within a xml-element
- Collocations
collocation analysis can be run for every solution
Note
client does not recognize absolute path to texts
Via the well-documented API programmers have a low-level access to the functionality of the xaira-server - the heart of the system. There is a prototypical implementation described in A2A/querying.
Xaira can be embedded into almost any web-server as an extension of php.
The use of php for various Web-servers is described in the appropriate documentation [php/INSTALL].
The hook of Xaira into php is as follows:
Install web-server + php
Install Xaira
take
php_xaira_php.dlland put it in the extension folder of php (by default../ext)Note
php_xaira_php.dllshould be in Xaira-install-folder but is not deployed with every versionadd following in the
php.ini:activate (uncomment ';') extensions:
extension=php_mbstring.dll extension=php_xsl.dll extension=php-xaira-php.dll
at the end:
[Xaira] corpus_path="C:\3IT\lingua\corpus\xaira\fk_issues\corpus_parameters.xml" data_path="C:\apps\Xaira"
- corpus_path
sets the corpus to use (linking to the
corpus_parameters.xml-file of the corpus)- data_path
sets the location of the Xaira-installation
start web-server
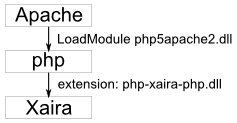
Working configurations:
| web-server | php | Xaira |
|---|---|---|
| Apache 2.0.X(59) | 5.0.X(5) | 1.16 |
| Apache 2.0.X(59) | 5.0.X(5) | 1.19 |
| Apache 2.0.X(59) | 5.1.X(6) | 1.21 |
| Apache 2.0.X(59) | 5.1.X(6) | 1.22 |
| IIS v 6.0 | 5.1.X(6) | 1.21 |
| IIS v 6.0 | 5.1.X(6) | 1.22 |
Note
Apache 2.2 only goes php 5.2.X, with which no Xaira-version works (except when recompiled)
Note
Under Windows IIS, it only works,
when the php.ini is placed in
C:\WINDOWS
Note
Trying to debug a problem with xaira-client I had to compile Xaira 1.19. This lead to a long-winded odyssey of putting together all the dependencies, so i found it useful to write it down:
xerces 2.7 [libxerces-c.so.27] - /usr/local/include/xercesc
ICU 3.6
php 5.2.0
libxml2 (2.6.16)
readline 5.2
termcap - copied from /etc to /
But this tedious work was probably only necessary because of the very old version of the Linux-distribution.
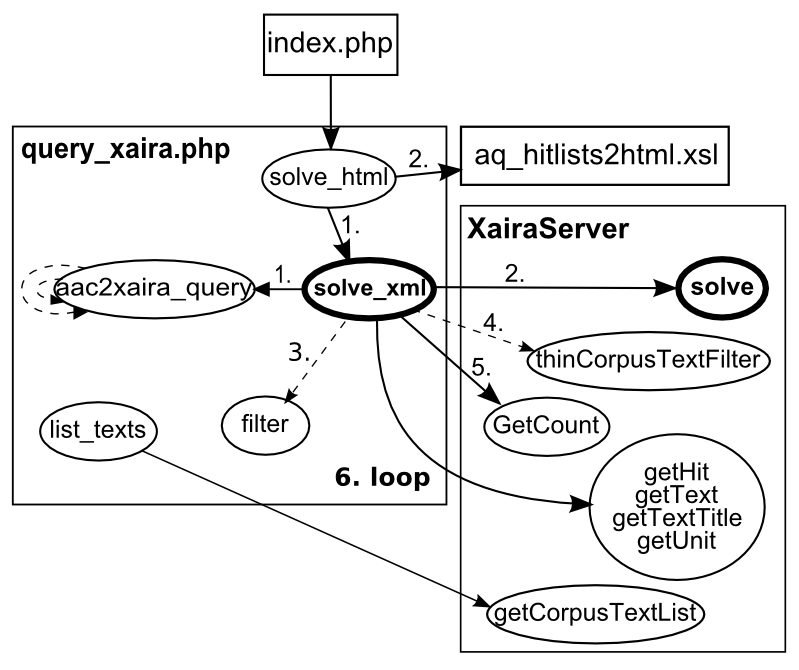
A rudimentary prototyping web-app [sources] is implemented, consisting of following files:
- index.php
the main entry point for web-access, contains the query-form
- query_xaira.php
contains all the functionality wrapped in functions
- aq_hitlists2html.xsl
is called in
solve_htmlto convert the result ofsolve_xmlinto a html-snippet- query_cli.php
a command-line entry-point it calls
solve_xml(thus results[xml]not[html])- testphp.php
only calls the
phpinfo()-function, which provides summary about the php-installation (settings, extension, etc.). Mainly for debugging purposes- vronk_style.css
some basic css-stylesheet
Note
$hit->getText() needs access to
texts - else Access Error.
If the location of the whole texts-set changed it is enough to
change the value of the parameter in
corpus_parameters and restart
web-server.
If individual files were moved or renamed, reindexing is necessary.
Note
The bottleneck is not the
solve()-method, but the
getText()-method, which has to retrieve the
context for the hit.
To not have to write the queries in the difficult-to-write cql-syntax, the test-app implements its own query-syntax, which is converted internally into CQL. This syntax is not yet fully
$op_distance = "#"; $op_wildcard = "*"; $op_filter = "@"; $op_cql = "<cql>"; $op_lm= "$"; $op_pos= "[";
XairaServer provides an easy low-level method to filter texts based on arbitrary (even multiple) conditions. One only has to provide a bit-array defining for each-text if it shall be included in the result or not:
$server=XairaServer::getXairaServer($CORPUS);
$n=$server->getCorpusTextList()->getCount();
$a=array();
$a[0]=$a[1]=0; // always exclude header and bib
$x=0;
// set up array of 0s and 1s for each text - 1 means in
for ($i=2;$i<$n;$i++) {
// apply condition
if (($i >= $start+1 && $i <= $end+1) || $cond=='all') {
$a[$i]=1;
} else {
$a[$i]=0;
}
}OPEN ISSUE
At the moment the test-app returns simply the first
$PAGING results (set as constant in
query_xaira.php).
If the data for one corpus are to be distributed (in space) (but queried together), the "distributed system" would have to be implemented (preferably in php). A mailing-list-post regarding this issue.
And a proposal of a reference model:
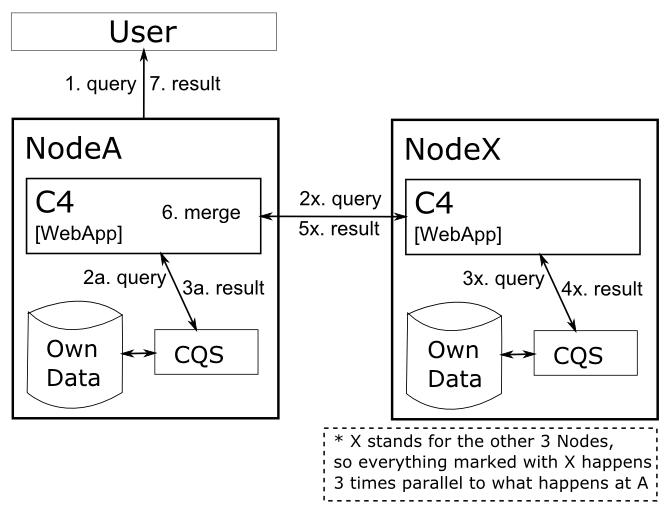
Note
C4 is the codename for the distributed system
to be implemented.
How to use bibliography in for filtering in queries and as meta-data in result?
How to apply partitions?
How to implement paging?
How to optimize getText()?
- xaira-info
- xaira-source
- xaira-tutorial
- xaira-header-docs
http://www.oucs.ox.ac.uk/rts/xaira/Doc/indexing.xml.ID=xairaspec
- new-header-issue
http://maillist.ox.ac.uk/ezmlm-cgi?1041:mss:672:hebgkobpmokdaloojicb
- new-header-issue-resolved
http://maillist.ox.ac.uk/ezmlm-cgi?1041:mss:682:lechbbllchpgjdnankic
- distributed-corpus-issue
http://maillist.ox.ac.uk/ezmlm-cgi?1041:mss:704:200703:hlidlbjapipnhiengnbo
- SourceForge.net: TN008 - Description of CQL
http://sourceforge.net/docman/display_doc.php?docid=33464&group_id=130289
- web-app-zip
http://www.vronk.net/resources/corpus/testapp_xaira_querying.zip